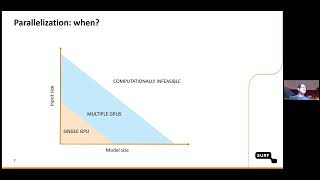
Context Notes: As datasets and models grow in complexity, mastering distributed training becomes vital.
Scalable Ml Lecture 2 4 Execution Parallelization - Useful Follow-Ups
Use this page to review Scalable Ml Lecture 2 4 Execution Parallelization with helpful explanations, comparison points, and reader-focused details while keeping the information easy to browse.
In addition, this page also connects Scalable Ml Lecture 2 4 Execution Parallelization with for broader topic coverage.
Useful Follow-Ups
Before relying on any single result, compare related pages and verify important facts from stronger sources.
General Info Guide
A clean overview helps readers understand Scalable Ml Lecture 2 4 Execution Parallelization before moving into details, examples, or connected topics.
General What to Compare
This section highlights the practical pieces readers may want before opening a more specific related page.
General Why It Matters
Context matters because Scalable Ml Lecture 2 4 Execution Parallelization can connect to nearby topics, related searches, and different reader intents.
Main details to review
- As datasets and models grow in complexity, mastering distributed training becomes vital.
Why this overview helps
Readers use this page when they need practical reminders for Scalable Ml Lecture 2 4 Execution Parallelization without relying on one result only.
Reader Questions
How should beginners approach Scalable Ml Lecture 2 4 Execution Parallelization?
Beginners should scan the overview first, then use related terms to narrow the subject into a more specific question.
What questions should readers ask about Scalable Ml Lecture 2 4 Execution Parallelization?
Check freshness, source quality, related examples, and any requirements or limitations before relying on one answer.
What should be checked first?
Readers should check the main context, important requirements, source freshness, and any details that may change over time.