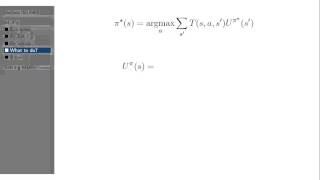Quick Reader Guide: 0.1 is the probability of transitioning to that state and then the reward again is going to be zero and the For more information about Stanford's Artificial Intelligence professional and graduate programs, visit: Andrew ...
Mdps The Value Function - Resource Quick Tips
This guide collects Mdps The Value Function with topic context, useful reminders, and related resources so the subject feels less scattered.
In addition, this page also connects Mdps The Value Function with for broader topic coverage.
Resource Quick Tips
For more information about Stanford's Artificial Intelligence professional and graduate programs, visit: Andrew ... COMPSCI 188, LEC 001 - Fall 2018 COMPSCI 188, LEC 001 - Pieter Abbeel, Daniel Klein Copyright UC Regents; ...
Reference Main Overview
0.1 is the probability of transitioning to that state and then the reward again is going to be zero and the For more information about Stanford's Artificial Intelligence professional and graduate programs, visit: In this video, you'll get a comprehensive introduction to Markov Design Processes.
Reference Important Notes
This section highlights the practical pieces readers may want before opening a more specific related page.
General Situation Notes
Context matters because Mdps The Value Function can connect to nearby topics, related searches, and different reader intents.
Main details to review
- For more information about Stanford's Artificial Intelligence professional and graduate programs, visit: Andrew ...
- COMPSCI 188, LEC 001 - Fall 2018 COMPSCI 188, LEC 001 - Pieter Abbeel, Daniel Klein Copyright UC Regents; ...
- For more information about Stanford's Artificial Intelligence professional and graduate programs, visit:
- 0.1 is the probability of transitioning to that state and then the reward again is going to be zero and the
Why this topic is useful
This reference can help when someone wants a lightweight hub for scanning and continuing research.
Reader Questions
Why do search results for Mdps The Value Function vary?
Start with the main context, then compare related entries and check stronger sources when exact details matter.
What does Mdps The Value Function usually mean?
Mdps The Value Function usually refers to a topic that needs context, related examples, and supporting references before readers make decisions or continue searching.
Why are related topics included?
Related topics help readers compare nearby references, explore similar searches, and avoid relying on one narrow result.