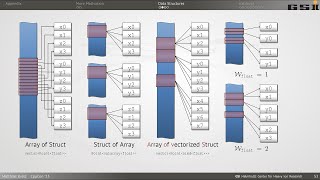
Topic Snapshot: Okay so i hope you can see my screen so i have i have this access sequence to a
Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon - Overview Search Context
This reader-first page connects Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon through important details, surrounding topics, common questions, and scan-friendly sections with enough variation for broader AGC-style topic coverage.
In addition, this page also connects Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon with for broader topic coverage.
Overview Search Context
This part keeps Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon connected to practical references instead of leaving it as a single isolated phrase.
Guide Snapshot
Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon can be reviewed through a clear overview first, then compared with related entries and supporting context.
Context Main Points
Important details can vary by source, so this page groups the most readable points into a scannable format.
Resource Next Steps
For changing topics, check updated sources and avoid depending on one short snippet alone.
Quick reference points
- Okay so i hope you can see my screen so i have i have this access sequence to a
Why this overview helps
A structured page helps readers move from a lightweight hub for scanning and continuing research.
Useful FAQ
What is the quickest way to understand Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon?
Start with the main context, then compare related entries and check stronger sources when exact details matter.
When should Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon be verified from official sources?
Official or primary sources are best when the information can affect decisions, costs, eligibility, safety, or deadlines.
Why do search results for Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon vary?
Start with the main context, then compare related entries and check stronger sources when exact details matter.