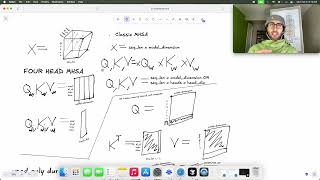
Context Starter: To produce one word, a language model has to look back at every word that came before it and run the entire stack of attention ... Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ...
Kv Cache Explained - Guide Decision Guide
This lightweight reference arranges Kv Cache Explained through important details, surrounding topics, common questions, and scan-friendly sections to support more niches without sounding like one fixed template.
In addition, this page also connects Kv Cache Explained with for broader topic coverage.
Guide Decision Guide
Try Voice Writer - speak your thoughts and let AI handle the grammar: The Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ...
Context Key Requirements
To produce one word, a language model has to look back at every word that came before it and run the entire stack of attention ... Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations?
Research Tips
Use the related entries as follow-up paths when you need more examples, current details, or alternative wording.
Reader Intent
This part keeps Kv Cache Explained connected to practical references instead of leaving it as a single isolated phrase.
Quick reference points
- To produce one word, a language model has to look back at every word that came before it and run the entire stack of attention ...
- Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations?
- Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ...
- Try Voice Writer - speak your thoughts and let AI handle the grammar: The
How this reference can help
The format helps reduce scattered browsing by giving a fast starting point without relying on one short snippet.
Useful FAQ
How does Kv Cache Explained connect to general?
Kv Cache Explained can connect to general when readers need context, examples, comparisons, or practical next steps inside the same topic area.
How does Kv Cache Explained connect to context?
Kv Cache Explained can connect to context when readers need context, examples, comparisons, or practical next steps inside the same topic area.
What makes Kv Cache Explained worth comparing?
Comparison helps readers avoid narrow results and find the angle that best matches their intent.